Function mq_smtp_in_message
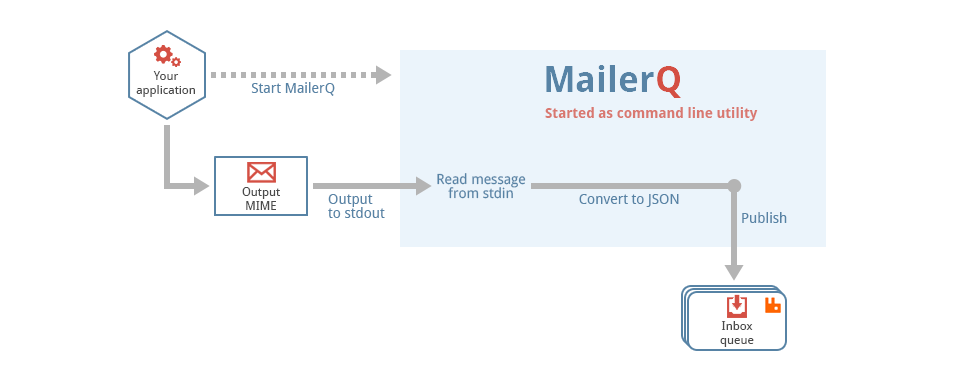
MailerQ calls this plugin function for every message that is received on the SMTP port. If you want to write a plugin that processes or modifies such messages, you can do so by implementing this function.
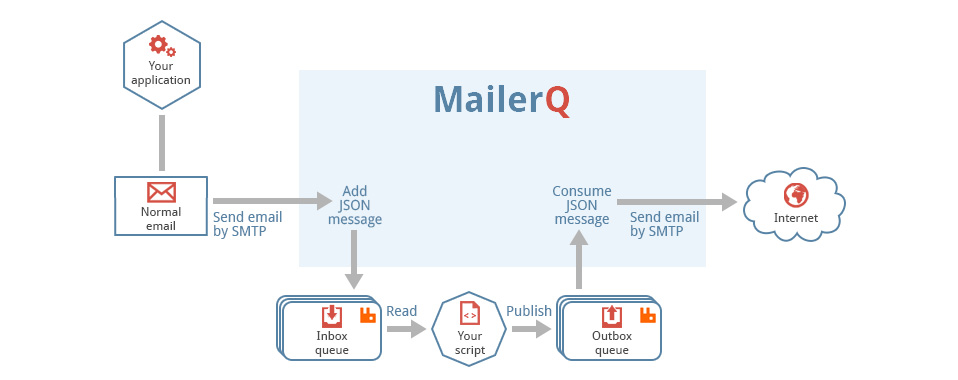
Your plugin may modify the JSON data in the MQ_Message. After all the plugins are ready with processing (and optionally modifying) the message, MailerQ will publish the JSON data to the RabbitMQ inbox queue.
Note that the SMTP protocol allows one to use multiple "RCPT TO" instructions to send a single MIME message to multiple addressees. If this is being used, the mq_smtp_in_message() function will also be called multiple times, once for every addressee.
bool mq_smtp_in_message(MQ_Context *context, MQ_Connection *connection, MQ_Message *message);
If your plugin returns true, MailerQ hands over control to your plugin, and you should also hand control back. For more information on how MailerQ plugins can interact with the event loop, and how control is passed to and from plugins, see the article about the MailerQ event loop.