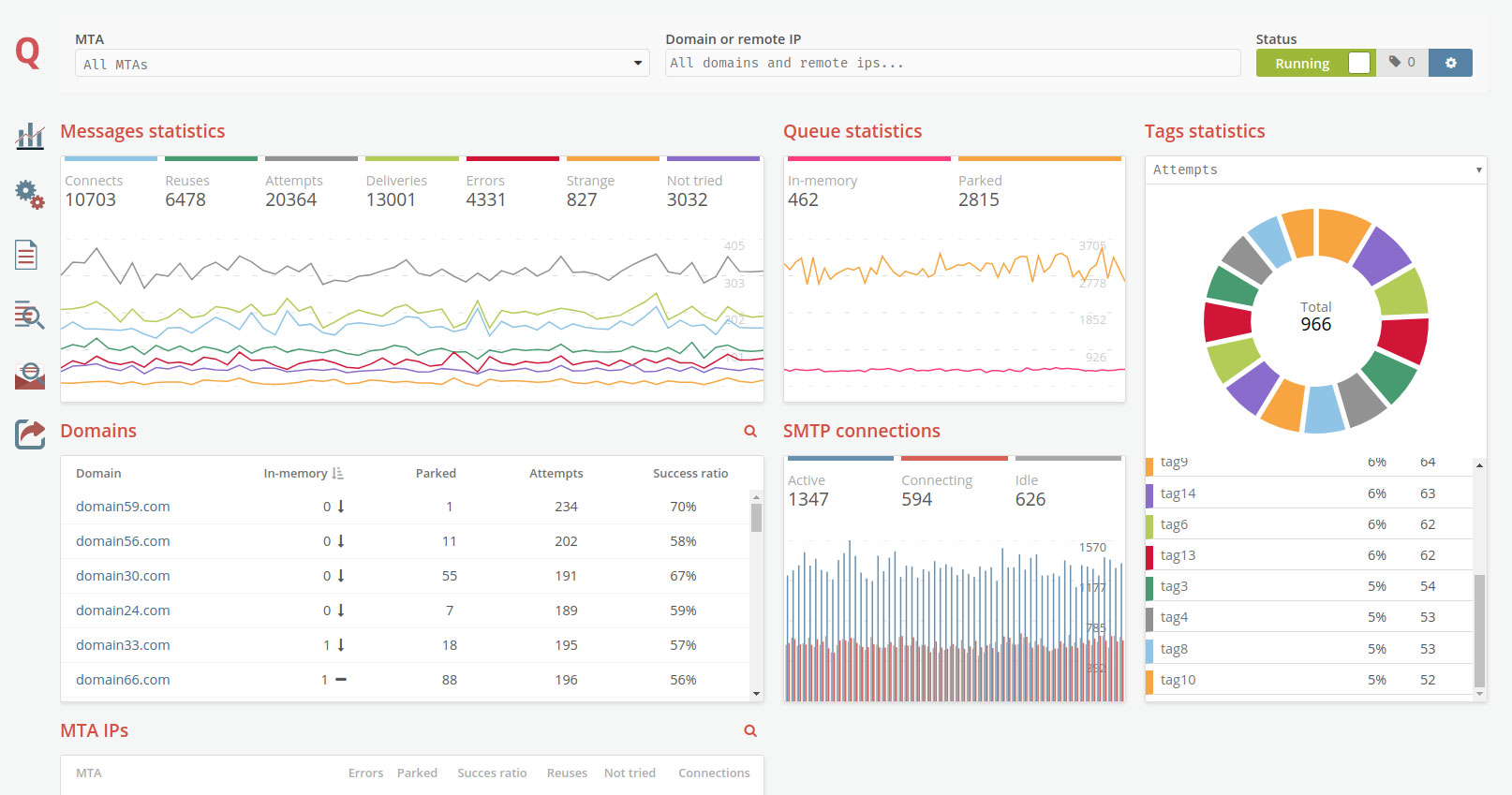
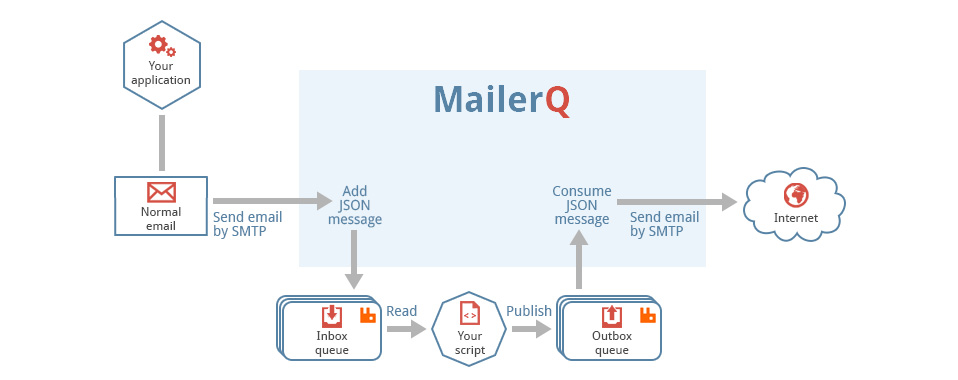
Structure MQ_Message
This structure is provided for plugin functions that work with message contents. It can be used to both retrieve and update message properties. If you use it for updating messages, you should be aware of the phase in the SMTP protocol that your plugin is intercepting: it is for example pointless to change the envelope address if the "MAIL FROM" instruction has already been sent.
All members in this MQ_Message structure are private, to interact with this structure, accessor functions have been created.
Functions that your plugin can export
A MQ_Message pointer is passed to your plugin when a message is received on the incoming SMTP port, and when it is about to be sent over an outgoing SMTP connection. If your plugin implements one of the following functions, it can get access to a message, retrieve information from it, or make modifications to it.
| Function name | Description |
|---|---|
| mq_smtp_in_message() | Called by MailerQ when a message is received on an incoming SMTP connection |
| mq_smtp_out_data() | Called by MailerQ right after it has sent the "DATA" command and is about the send MIME data |
Access to the raw JSON data
The MQ_Message structure is essentially a wrapper around the original JSON data that was loaded from RabbitMQ (if your plugin interacts with outgoing messages), or a wrapper around the JSON data that is going to be published to RabbitmQ (for incoming messages). Your plugin can get access to the JSON data, and make modifications to it.
| Function name | Description |
|---|---|
| MQ_json() | Get access to the JSON data of a message |
Access to derived properties
Besides the JSON, you can also access derived properties. You do not have to inspect the JSON directly, but can use one or more of the following methods to get access to the message properties:
| Function name | Description |
|---|---|
| MQ_envelope() | Get access to the envelope address |
| MQ_setEnvelope() | Set the envelope address |
| MQ_recipient() | Get access to the recipient address |
| MQ_setRecipient() | Set the recipient address |
| MQ_mime() | Get access to the MIME data |
| MQ_setMime() | Get the MIME data |