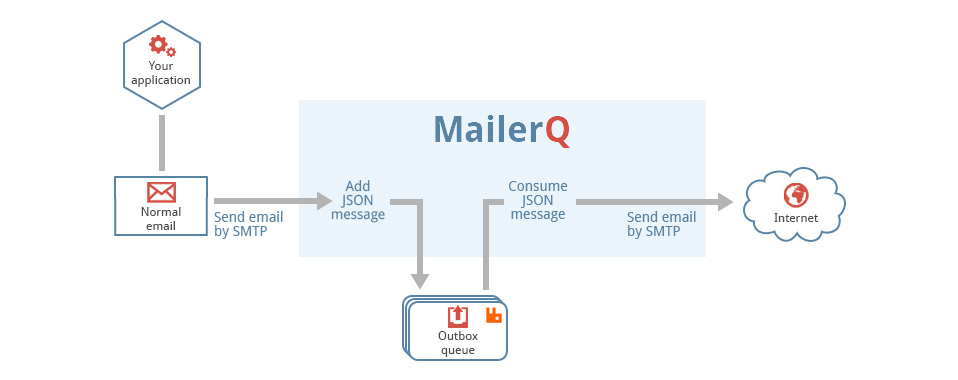
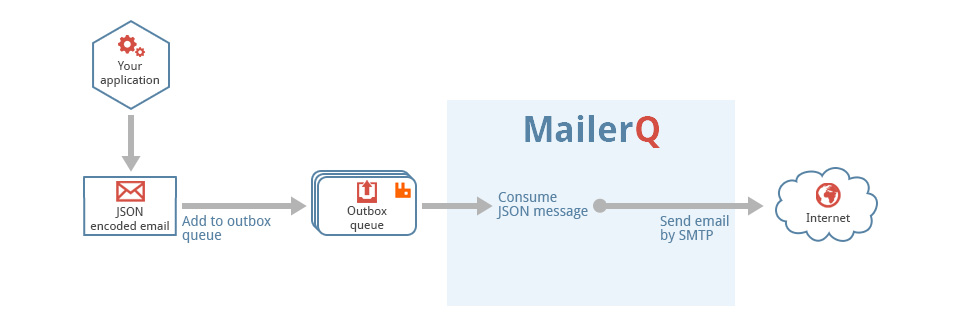
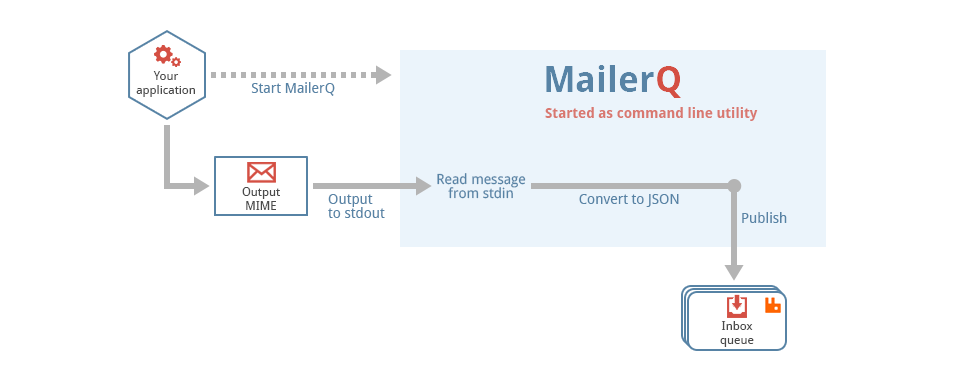
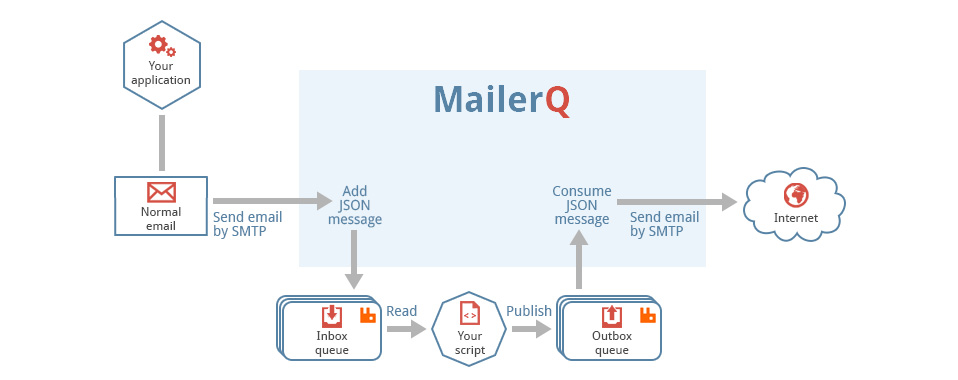
AmqpInit
Mailerq-amqpinit is a simple Linux application for setting up queues and exchanges in RabbitMQ. It is an application independent from MailerQ, and can be helpful in, for example, startup scripts to ensure that a RabbitMQ server is correctly configured. It takes a JSON string from standard input, and creates all the exchanges and queues that are defined in that file.
Installation
The application is stored in our APT repository. If you have already enabled our APT repository, you can install it with this command:
sudo apt install mailerq-amqpinitRunning
You typically run this script with one command line argument, and you pipe the JSON input into the program:
amqpinit amqp://user:password@hostname/vhost < input.jsonThe amqp:// address holds the address of a RabbitMQ server.
Format of the JSON input file
The JSON input file typically holds a JSON array with all the resources (queues, exchanges and bindings) that are to be created. For example:
[ {
"type": "queue",
"name": "my-queue",
"durable": true,
"arguments": {
"x-queue-type": "classic"
}
}, {
"type": "exchange",
"name": "my-exchange",
"durable": true,
"arguments": {
"x-max-length": 1000
}
}, {
"type": "exchange",
"name": "my-other-exchange",
"exchangetype": "fanout",
"durable": true
}, {
"type": "binding",
"exchange": "my-exchange",
"queue": "my-queue",
"routingkey": "my-routing-key"
}, {
"type": "binding",
"exchange": "my-exchange",
"target": "my-other-exchange",
"routingkey": "my-routing-key"
} ]For each item in the array, the following properties are supported:
- type: the type of resource to be declared. Supported are "queue", "exchange" and "binding".
- name: the name of the resource (like the queue or exchange name).
- exchangetype: the type of exchange: "fanout", "direct", "topic", "headers", "consistent_hash".
- exchange: the from-exchange to bind.
- queue: the target-queue to bind.
- target: for bindings between exchanges: the target-exchange.
- routingkey: the routingkey for bindings.
- arguments: additional arguments for creating the resources (mainly useful for queues)
- durable: to create durable resources (to survive a restart of RabbitMQ).
- autodelete: create a queue that is auto-deleted.
- passive: do not create anything, just check for existance.
- exclusive: create an exclusive queue.
- internal: create an internal exchange.
Not all properties are meaningful for all resource types. For example, the "exchangetype", "queue", "target" and "routingkey" properties only make sense for exchanges. The properties "durable", "autodelete", "passive", "exclusive" and "internal" are all booleans and are available for completeness because the AMQP protocol supports them. Realistically, only the "durable" property is useful.